-
It’s on. #coffee

-
Font too big; DR
From the “Shouting into the wind” department: oversized body text is a menace on programming blogs I read. My theory is that these bloggers are running Linux at odd pixel densities (i.e. 1440p laptops) and they can’t read text at normal sizes, so they size everything up as a matter of course. Today I looked at the CSS on one and found “font-size: 1.2rem” which (I’ve now learned) means “make the body text 20% bigger than the reader wants it to be.” Please don’t do this. I might want to read what you have to say, but I often won’t have the patience to adjust my browser to accommodate your questionable life choices.
-
There have been some tough days recently, but on a day like today it’s good to be Charlie 🐕 🕯🕯🕯🕯🕯 🕯🕯🕯🕯🕯 🕯🕯🕯

-
SwiftUI, Catalyst, and now unmodified iPhone and iPad apps. How many ways do we need for iOS developers to target Mac? All of them, apparently.
-
Does featuring both Docker and Linux under Parallels in the #WWDC keynote suggest that macOS on ARM will have an even less Unix-y terminal environment than in the past?
-
Trying to print a partially-evaluated list in Haskell (with partial success)
Working on exercises from Okasaki’s Purely Functional Data Structures involving lazy evaluation and wondered if it would be possible to introspect on the structures in memory and see what’s actually going on at runtime.
Note: Scala’s lazy
Streamdoes this, for the cells but not their contents:scala> val fibs: Stream[Int] = 0 #:: 1 #:: fibs.zip(fibs.tail).map { case (a, b) => a + b } fibs: Stream[Int] = Stream(0, ?) scala> fibs(6) res6: Int = 8 scala> fibs res7: Stream[Int] = Stream(0, 1, 1, 2, 3, 5, 8, ?)I found this
evaluatedfunction on Stack Overflow (with a whole list of caveats), and slapped together a simple hack. It works for me with GHC 8.6.5 and-O0, but not in ghci or with optimization turned on.An example test:
it "shows a list with several cells evaluated" $ do let lst = [1..10] :: [Int] putStrLn $ tshow $ take 3 lst -- actually demand the first three values showLazyList lst `shouldBe` "1 : 2 : 3 : ..."And the code:
import GHC.HeapView import System.IO.Unsafe (unsafePerformIO) -- [stackoverflow.com/a/2870168...](https://stackoverflow.com/a/28701687/101287) evaluated :: a -> IO Bool evaluated = go . asBox where go box = do c <- getBoxedClosureData box case c of ThunkClosure {} -> return False SelectorClosure {} -> return False APClosure {} -> return False APStackClosure {} -> return False IndClosure {indirectee = b'} -> go b' BlackholeClosure {indirectee = b'} -> go b' _ -> return True showLazyList_ :: (Show a) => String -> String -> [a] -> IO String showLazyList_ elemThunkStr tailThunkStr lst = do evaluated lst >>= \ case True -> case lst of h : t -> do hStr <- evaluated h >>= \ case True -> pure (show h) False -> pure elemThunkStr tStr <- showLazyList_ elemThunkStr tailThunkStr t pure $ hStr <> " : " <> tStr [] -> pure "[]" False -> pure tailThunkStr -- |Show the contents of a list, only so far as have already been evaluated. Handles unevaluated -- elements and cells. Uses unsafePerformIO shamelessly. showLazyList :: (Show a) => [a] -> String showLazyList = unsafePerformIO . showLazyList_ "?" "..." -
I went through my drawer and pulled out all the cables with USB (A) on one end. What a great run that port has had. I like the idea of hanging these all up somewhere where I can see what’s what. Also, some of these might not actually be worth holding onto 🤔

-
Made my own mask from stuff in the house. Glad to be able to protect myself and my neighbors without taking a “legit” mask away from someone who needs it more. Thanks, ragmask.com!


-
Spring, 2020

-
Simple Techniques for Debugging SwiftUI Views
SwiftUI
Views are written in a declarative style, which can be a nice, compact way to construct a large tree of sub-views, but it also can make it surprisingly hard to do certain things.For example, suppose you’re debugging your View and you’re wondering about the value of some state variable at a certain time. You might try writing this:
struct MyView: View { var label: String // WARNING: this doesn't compile! var body: some View { print(“The label is: \(label)”) Text(label) } }If you do, you’ll see this very un-helpful error:
Function declares an opaque return type, but has no return statements in its body from which to infer an underlying type
Note: error messages are supposed to be much better in Swift 5.2, which is available in Xcode 11.4 as of yesterday, so things might already be better on that front, but the code still won’t compile.
Fix #1: add
returnIf you stare at that error message for a while, you might be inspired to try changing that last line to
return Text(label), and in fact that will work.Now suppose your View is a little more interesting, with more than one sub-view, and there are different things you want to log:
// WARNING: this doesn't compile! var body: some View { VStack { print("The label is: \(label)") Text(label) print("There are \(label.count) characters") Text("abc") } }This doesn’t work, and you can’t fix it by adding
return. If you play around with it a little bit, like I did, you’ll find that you don’t get far by trying to treat these View expressions as regular code blocks. Instead, think of it as a special language just for Views, which just happens to use some of Swift’s keywords (likeifandelse).Fix #2: put it in a regular function
You can get back to the familar world of “normal” Swift code by just putting the logging in a
funcand making it so the func’s result is part of the View expression. Here’s one way to do that:func trace<T>(msg: String, _ result: T) -> T { print(msg) return result }Since this function can accept any value, you can wrap it around whatever part of the expression you like, which is either clever or ugly, depending on how you look at it:
var body: some View { VStack { trace(msg: "The label is: \(label)", Text(label)) Text( trace(msg: "There are \(label.count) characters", "abc")) } }Fix #3: something prettier
A nicer idea (thanks to Rok Krulec here) is to set up your func to build a special View that doesn’t draw anything, but just does your logging when it’s constructed and then hopefully stays out of the way:
func Print(_ msg: String) -> some View { print(msg) return EmptyView() } var body: some View { VStack { Print("The label is: \(label)") Text(label) Print("There are \(label.count) characters") Text("abc") } }Pretty slick.
Fix #4: use the UI, Luke
On the other hand, if you’re using
printto debug your UI, in a sense you’re doing it wrong — after all, you’re not writing a command-line app! What’s the UI equivalent ofprint? instead of spewing debug all over the console, how about spewing it all over the UI? Sounds great, right?More practically, printing to the console doesn’t work when you’re using SwiftUI Preview to see the effect of your edits in real time. When you do that,
print-ed output doesn’t seem to go anywhere as far as I can tell.Here’s one way to make that happen:
var body: some View { VStack { Text(label) .annotate("The label is: \(label)") Text("abc") .annotate("There are \(label.count) characters") } } ... extension View { func annotate(_ msg: String) -> some View { self.overlay( Text(msg) .fixedSize(horizontal: true, vertical: true) .offset(x: 100, y: 10) .font(.caption) .foregroundColor(.gray) ) } }This way, each line of debug output is displayed in the View itself. Each message floats below and to the right of the sub-view it’s attached to. Using
overlayensures that the View’s layout is unaffected by the dangling messages, andfixedSizeallows each one to expand beyond the size of its corresponding View. The rest of the attributes just hopefully make the annotations a little less prominent so the UI is still recognizable.Anyway, those are some things I’ve found to be interesting and perhaps useful. SwiftUI’s new, declarative style requires some new tools and some new ways of thinking. I’m enjoying experimenting to figure out what works, and I hope you found these experiments interesting, too.
-
Mouse support in the iPadOS 13.4 beta feels surprisingly natural and also uncanny at the same time. It’s clear a lot of thoughtful design work went into it. I think it’s great that they’re actively expanding the ways the platform can be used.
-
I turned my SwiftUI hack into a (crude) app. Much more fun to play with on the phone.

-
Visualizing Prime Factors with SwiftUI
Following a recent post, I enjoyed revisiting Brent Yorgey’s Factorization Diagrams (by the way, this in-browser animation is pretty great, too.)
I immediately wanted to try some variations, and didn’t really feel like figuring out how to compile Yorgey’s Haskell, let alone how to do something interactive with it. And then I had the thought that this might be a nice way to experiment with SwiftUI: it’s graphical, declarative, and simple enough for a novice like me (or so I hoped).
After stumbling around in a Playground for while, here’s what I came up with:
VStack { layout(n: 3) { layout(n: 2) { Circle().foregroundColor(.blue) }} }That is, draw 3 sets of 2 blue circles each, visualizing the prime factorization:
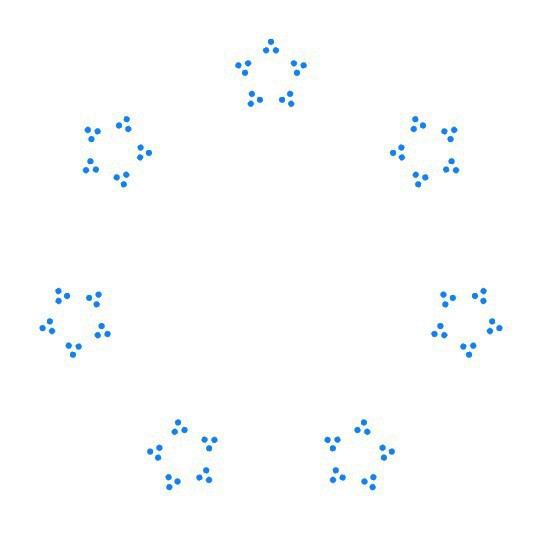
6 = 2·3(see the first image.)layoutjust applies some rotation, scaling, and offsets toncopies of its argument:// Two fairly arbitrary parameters: let RADIUS: CGFloat = 100 func scale(_ n: Int) -> CGFloat { return 1/CGFloat(n) } func layout<V:View>(n: Int, d: @escaping () -> V) -> some View { func position(i: Int) -> some View { let t = Angle.degrees(Double(i)*360/Double(n)) return d() .rotationEffect(t) .scaleEffect(scale(n)) .offset(x: RADIUS*CGFloat(sin(t.radians)), y: RADIUS*CGFloat(-cos(t.radians))) } return ZStack { ForEach(0..<n, content: position) } }Additional nested calls produce more interesting designs (the second image):
layout(n: 7) { layout(n: 5) { layout(n: 3) { Circle().foregroundColor(.blue) }}}I’m pretty happy with this as far as it goes, but so far I haven’t been able to get the fancy SwiftUI types to understand an unfolded version so I could make a single call like
layoutFactors([5, 3, 2, 2])orlayoutPrimeFactors(60).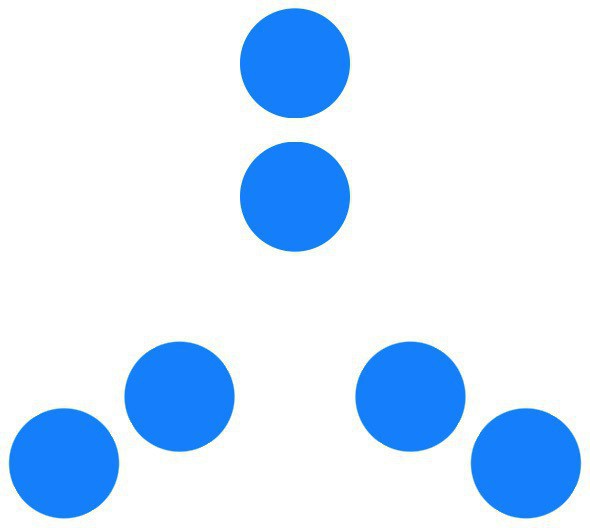
-
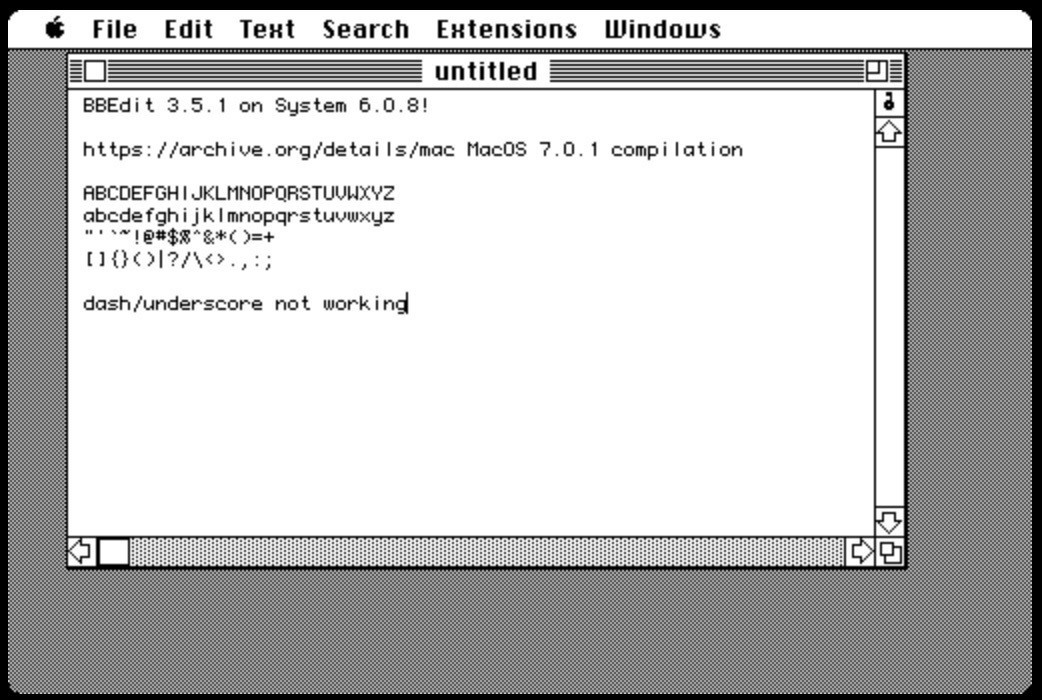
Went looking for an accurate reference for classic bitmap Monaco 9 and ended up running BBEdit 3.5.1 on System 6. Thanks, archive.org! https://archive.org/details/mac_MacOS_7.0.1_compilation What a wonderful place the internet can (still) be when you look in the right place.
-
A Smaller, "Cheaper" Nand2Tetris CPU
I’ve done three different “enhancements” to the nand2tetris design now, and each one has added complexity in order to make programs run faster, or to allow larger programs to run.
That’s fun, but in a way making the chip better by using more gates is the easy problem. A trickier challenge is to make a smaller chip that’s still as useful as the original. It seems almost impossible; the nand2tetris design is so cleverly simple, how can we take anything away and still be able to do what it does?
Eventually I hit upon a simple idea. About 45% the ~1,200 gates of the chip go into its very wide ALU. 16 bits is a lot for a chip of this size; most design on this scale in the 1970s and ‘80s were 8-bit or mixed 8/16-bit architectures. What if I build a chip with only a single 8-bit ALU, and use two cycles to push the two bytes of each input through the ALU?
You can see how that worked out in alt/eight.py.
There’s some extra logic to keep track of cycles in pairs: In the “top-half” cycle, the ALU computes the low-byte of its result, which is stored in a simple latch (8 DFFs), along with a carry bit and the ALU’s
zrcondition bit. In the following “bottom-half” cycle, the ALU computes the high-byte (incorporating the carry from the previous result). A number of the CPU’s tasks happen only in the bottom-half cycle: the PC is incremented (or loaded, if jumping), the registers are updated from the ALU/memory, memory is written, etc.The narrower ALU is in fact just about half the size of the original (286 vs. 560 gates.) Unfortunately the rest of the chip gets more complicated to deal with the two-cycle cadence. There are now two possible sources for each ALU input, as well as 19 new DFFs to hold results between cycles, and assorted logic to keep track of what happens when. In the end, the chip is smaller, but only by about 18%, nowhere near half the size of the original. Non-ALU logic is up to 744 from 682 gates.
So, partial success I suppose. I wonder what a late-‘70s microprocessor engineer would have made of an 18% savings in chip area that came with a 50% reduction in speed? Would this chip have sold as a low-cost alternative?
-
More Nand2Tetris
I’m still having fun with my From Nand to Tetris toolchain (https://github.com/mossprescott/pynand).
Just merged 2 experimental CPU variants: one that adds complexity to do more in fewer cycles, and another that’s also more complex, runs slower, but can fit a much larger program in the same ROM space.
Still wondering if there’s a way to make a smaller CPU, but inspiration is lacking so far.
-
Okasaki’s Binomial Heap with Dependent Types in Haskell
I’ve been reading Okasaki’s Purely Functional Data Structures with work friends at TVision, and decided to get a little overly ambitious with the exercises on Binomial Heaps in chapter 3. This is a curious data structure with some unusual invariants which the author maintains by storing extra information in the nodes. Then he shows how some of the information can be inferred from the structure, saving space. It occurred to me that it all can actually be tracked in the types, saving even more space. Or so it seemed, anyway. I had to give it a try.
If you want to skip the intro and take a look at the code I came up with, here’s the gist.
The data structure is built up in two steps. First, a Binomial Tree is a tree with an interesting recursive structure:
- A rank-n tree contains a root value and n child trees
- Each child is a binomial tree, with ranks from 0 to n - 1
- It follows that a rank-n tree contains 2ⁿ values (i.e. it’s always full)
You can represent this with a simple ADT which might look like this in Haskell:
data BinomialTree a = Node a [BinomialTree a]But that shape doesn’t express the invariants about the rank of each tree and its list of children, so to help keep track of that Okasaki adds the rank to each node:
data BinomialTree a = Node Int a [BinomialTree a]That way operations on these trees can check and maintain their ranks. But the compiler isn’t helping; a bug in any function can construct a non-sensical tree. With a little bit of dependent typing, we can do better:
import GHC.TypeLits ... data BinomialTree a (rank :: Nat) = Node a (SizedList (BinomialTree a) rank)Notice that a tree’s rank now appears only in the tree’s type.
SizedListis a list in which eachconsrecords the length of the list, and it also requires the types of the list’s elements to be a matching series (see the gist for the details). For example, aBinomialTree Int 2contains aSizedList … 2whose elements areBinomialTree Int 1andBinomialTree Int 0, all of which matches the invariants given above. This works pretty well; the compiler is now able to check that the ranks of a Node and its children are related in the expected way. If you try to put one together wrong, the compiler helpfully points out your mistake (well, you get an error that says something likeexpected type 0 doesn't match actual type 1…) So far, so good.Next, the Binomial Heap data structure is built on Binomial Trees, and mirrors them in an odd way: A Binomial Heap is a (flat) list of trees with increasing ranks. The author’s type is again (too) simple:
type BinomialHeap = [BinomialTree]. Again the trees are expected to form a series of increasing rank, except this time there can be gaps in the sequence.Jumping to the chase, here’s a strong type for these lists:
type BinomialHeap a = RankedList (MaybeF (BinomialTree a)) 0What’s interesting here is
RankedList, which is a kind of opposite ofSizedList; the head of a RankedList shares the list’s overall type (e.g. 0, in a heap), and the tail’s type is one greater. This type works out in the same way, making it impossible to construct a value in theBinomialHeaptype that violates the invariants. Note: there’s no need to track any kind of overall rank for the heap, it’s always a list of trees starting from rank 0.One of the fun things that comes up is the observation that the children of a Binomial Tree, when reversed, form a valid Binomial Heap. For that to work out, I needed to be able to write
reverseSized :: SizedList f len -> RankedList f 0(that is, given a SizedList containing elements with types[f len-1, ... f 0], construct a RankedList containing the same elements starting fromf 0.) It wasn’t obvious to me that that would even work, and it was a challenge to get right, but the result is wonderfully simple.I wonder: what would an opposite reversing function look like?
reverseRanked :: RankedList f 0 -> SizedList f lenwon’t work, because the RankedList might not have the right number of elements for the desired type. I can think of a few possibilities; might need to hack on this some more sometime.There were more fun puzzles to solve along the way. Overall, I think Haskell’s facilities for dependent typing worked pretty well here. I don’t think I want to write code like this all the time, but if I was implementing a tricky data structure like this for production use, I would definitely give it a try.
-
Re-posting: I spent some time over the holidays making a from-scratch implementation of the exercises from the amazing From Nand to Tetris course/book. 100% Python, tons of fun to work on, and now ready for others who might be interested to have a look at: github.com/mosspresc…
-
I haven’t posted in ages, but I’ve been doing some interesting software projects and experiments lately, so that’s all about to change. I’m back, baby!
subscribe via RSS